Finding Words That Rhyme (C++)
In this post I’ll explain a basic approach to finding English rhymes programatically. The implementation I put together makes use of the The CMU Pronouncing Dictionary. Fair warning: I’ve never researched this topic, so there may be better solutions out there. I wrote this just for fun.
The CMU data file includes a huge list of English words, along with corresponding phonetic symbols. The number at the end of each vowel symbol indicates a stress variation. Here’s a custom excerpt for the example that I’ll discuss throughout this post:
EYES AY1 Z
LIES L AY1 Z
PRICE P R AY1 S
PRIZE P R AY1 Z
REPLIES R IH0 P L AY1 Z
RICE R AY1 S
RISE R AY1 Z
SIZE S AY1 Z
THIGHS TH AY1 ZGiven the dictionary above, if we want to find words that rhyme with “EYES”, we’d expect to match everything except “PRICE” and “RICE”. Depending on whether we’re looking for exact rhymes or just a matching ending, “REPLIES” could go either way.
So how can we do this? For starters, if performance doesn’t matter, the dictionary data has everything you’d need for a brute force search. For a given candidate word, you could start from the last symbol and work backwards to find words that have matching symbols until you hit some stopping criteria, such as moving past a vowel.
In the example above, you’ll notice all of the rhyming words, like “PRIZE” [P R AY1 Z] and “THIGHS” [TH AY1 Z] have the same symbols from right to left until you cross AY1 (a vowel sound.)
Brute force would work, but would be quite slow for the full dictionary. To make things snappier, the approach I implemented builds up a tree-like structure (akin to a trie) at load time, creating nodes for each symbol type and inserting each word based on its symbols from right to left. The words can be stored at any level where they happen to terminate, not just leaves. It’s easier to visualize than explain…
The example data set above would look something like this after loading:
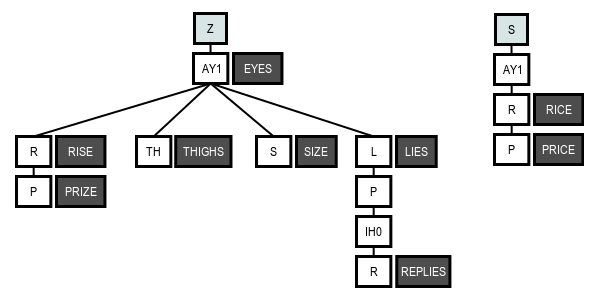
To find rhymes, we can now simply choose a stopping condition (such as first vowel), and start walking the structure to find words that share the same endings. If we know the stopping condition beforehand, and know that it won’t change, we wouldn’t necessarily need to build out the whole tree as shown above. We could just insert the endings and then store all further matching words at the stop nodes for faster retrieval. But for now let’s consider the whole tree to help distinguish between match types…
As an example, if our input word is “THIGHS”, using the symbols from right to left, we look for node Z (TH AY1 Z) and disregard everything else adjacent. We continue down from it to AY1 (TH AY1 Z.) Here we found our stopping condition (a vowel), which means we can start gathering words at or below this node. To do so, we can walk each branch– collecting any words we find along the way– until we hit the end or we encounter another vowel. In this case, that would include: “EYES”, “RISE”, “PRIZE”, “THIGHS”, “SIZE”, and “LIES.” The word “REPLIES” would not match because once you’ve walked down [L] – [P] – [IH0], gathering stops because we’ve hit another vowel (IH0.)
For more relaxed matching, we can discard the “encountering another vowel” bit and just match the endings. That would mean grabbing everything at or lower in the structure after hitting the initial stopping criteria. This approach would allow matching words like “end” to “comprehend” and “attend”, rather than only “perfect” rhymes like “send” or “trend.”
For even more relaxed matching, we could do things like combine similar sounding consonant symbols at load time. The result would be a greater emphasis on matching vowel sounds. Words like “cave” and “safe” don’t actually rhyme but often still “sound like” rhymes in things like song lyrics.
As a general note, it seems that rhyming is a bit of a squishy concept. Even for the supposedly “perfect” rhymes described above, pronunciation, accents, etc, make a huge difference in what an individual considers a rhyme in the first place. The CMU dictionary provides a great starting point, but it’s likely not perfect for all applications.
Source Code and Implementation Notes
My C++ implementation is available here. This is essentially hobby code. If I were going to use this in a production application or game, a few things to consider would be:
-
The slowest part is loading and parsing the dictionary file. Converting this to a binary format that can be loaded directly into the run-time data structure would speed things up.
-
As mentioned above, if the stopping condition is known beforehand, the entire tree mightn’t need to be built out. Having the larger structure allows for more flexible matching patterns and interesting word relationships, but for simpler rhymes it’s rather wasteful. Beyond that, if the application space is really limited, all of the rhymes could just be dumped to a big file.
-
This implementation has tons of small allocations for strings and nodes. This could be massively improved with more careful and cache-friendly memory management.
-
There’s a bit of nuance with regard to the vowel stress variants that would need to be addressed. For example, in the data, the word “CRAPPY” ends with IY2, while “SCRAPPY” ends with IY0.
That’s all for now. I may do a deeper dive in the future, but the results from this approach are pretty good. Here’s a dump of some search examples: rhyme-results.txt